By: Aaron Daniel, with assistance from Claude Opus 4.8
I built a loop that writes software, finds its own bugs, fixes them, reviews its own fixes, and merges them, with no human inside that cycle. I stayed in control from outside it, through the tests. I want to describe how that works, because what actually holds it up isn't the part that looks impressive, and almost nobody building these workflows is honest about the difference.
First, what got built. I put together a framework for hosting agents on the Claude Agent SDK, with one MCP server as an agent registry and another as a shared workspace so the agents could collaborate, plus a shared skill repository and skills living inside individual agents. To test and demo it end to end, I built a UI that lets a user spin up agents and MCP servers, run tools, and watch the topology react in real time. Getting the UI to behave was the hard part. A real-time visualization of a live multi-agent system has a lot of surface area for things to go subtly wrong.
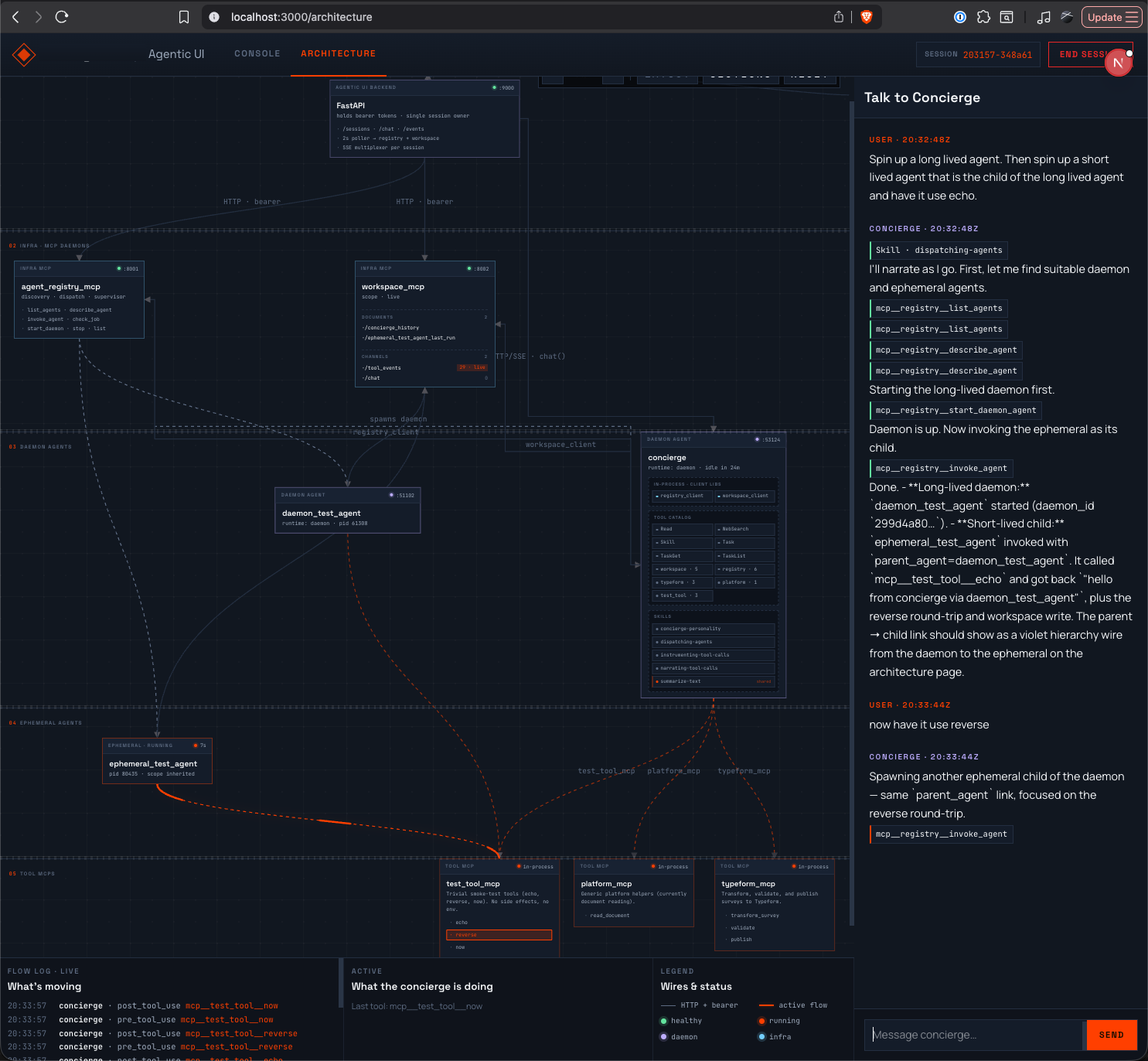
The architecture page during a live session. On the right I'm telling the concierge to spin up a long-lived agent (daemon) and a child that completes a task and exits (ephemeral); on the left the topology redraws itself as they come up, with tool calls pulsing along the wires. This is the system I drove by hand to find the bugs no test had caught yet.
That's the system. The interesting part is how I got it working.
The model writes faster than anyone can read
When you build with Claude Code, it writes a lot of code very fast. Fast enough that rereading all of it stops being realistic. The model can produce more in an hour than I can carefully review in a day. This usually gets framed as a discipline problem, as if the responsible move is to slow down and audit every line. But that quietly puts the human back in the position of rate limiter. If the point of the tool is speed, and your quality-control method is reading every diff, you've capped the system at human reading speed and thrown away most of what made it worth using.
So the real question isn't "how do I review all of it." It's "where does a human actually need to be, and where am I just slowing things down." The old answer was that the human reads the code. That made sense when humans and machines wrote code at comparable speeds. It doesn't anymore.
I reviewed the tests, not the code
The move I landed on is to review the tests instead of the implementation, at the resolution where my judgment beat the model's and nowhere else.
That meant three passes at decreasing detail. I had the model generate a one-line summary of every user acceptance test it intended to write, and I read all of them. Not to verify any single test, but to verify the set: does this cover the behaviors that matter, and where are the holes. That's a coverage question, and it's the one thing in this process a human who understands the system can answer better than the model can. It's also cheap to review, because it's one line each.
Then I had it expand the approved cases into step-by-step workflows, and I spot-checked a sample. Enough to confirm the translation from "what to test" to "how to test it" was sound, not enough to read every one.
Then it wrote the actual test code and ran it, and I didn't read that at all.
That's the whole idea made concrete. My attention was densest where it was most leveraged, the coverage layer, and absent where I was just slower than the machine. Most people who try this either review everything, which brings the bottleneck right back, or review nothing, which means there was never a human in the loop. The skill is finding the altitude where a human is still irreplaceable and delegating everything below it.
The agents fixed their own bugs without me
Here's where it goes further than "review the tests, trust the code."
Claude Code can run a long time on a single prompt, so I set up the failure-handling to need no human at all. When a test failed, the instruction was to keep running the rest of the suite but spin up a subagent to find the root cause, fix it, open a PR, and have a second subagent review that PR. By the time the full run finished, there'd be a stack of PRs, each written and reviewed by subagents. Those merged, the suite ran again, and the cycle repeated until everything passed.
That loop builds and repairs software with no human in the inner cycle. I start a run, it grinds to green, and I'm not part of any individual fix along the way. The test suite stopped being just the thing that let me skip reading the code. It became the fitness function for an autonomous build loop: I set the bar the code had to clear, and the agents drove toward it on their own.
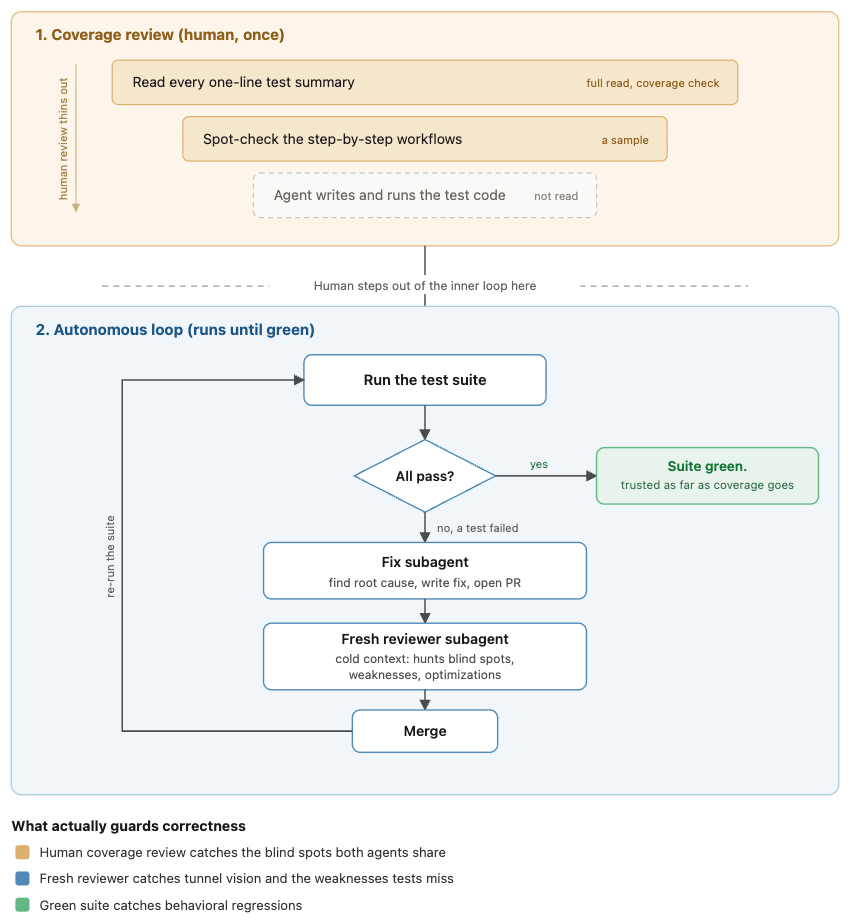
I review coverage at the top, at decreasing detail, and never read the implementation. Below the line, the agents run the test-fix-review-merge cycle on their own until the suite is green.
Between runs, I'm the one driving
That inner loop is the part that looks like magic, so it's worth saying plainly where the magic stops. "No human in the cycle" describes a single run, not the project. Around the autonomous loop is an outer one that is entirely mine. When a run finishes green, I drive the software myself, the way a user would, and I find the things no test caught yet: the interaction that feels wrong, the case nobody specified, the behavior the suite was blind to. Each of those becomes a new test. Then I confirm the suite is green against the raised bar and start the next run.
So control never left. It moved to the test layer and stayed there. I'm not reviewing components; I'm deciding, every cycle, what the software has to prove before I'll trust it, and writing that decision down as a test. That is the actual argument for test-driven development when an agent is doing the building. The tests are a rigid frame that lets you build the whole project without reading every piece of it, and the rigidity is the point. A passing suite means something only because I keep raising what it has to pass. It is also how I deal with the obvious objection, that tests only catch what you thought to test: I catch the rest by driving the thing myself, and the moment I find one, it stops being unforeseen and becomes a test that holds forever after.
The reviewer comes in cold, on purpose
The subagent that reviews each fix is not the one that wrote it, and it doesn't carry the fixer's context. That matters more than it sounds. The agent that wrote the fix has already convinced itself the fix is right; it has a stake in its own reasoning. A fresh agent comes in with no investment in the approach, and you can point it straight at the things an author is worst at seeing: blind spots, weak assumptions, code paths the tests don't exercise, optimizations the author didn't reach for. The uncontaminated context is the whole value, and treating the reviewer as a rubber stamp wastes the most useful property it has.
What it can't do is escape the priors it shares with the fixer. Both are instances of the same model. If the model has a systematic misunderstanding, some API semantic it consistently gets wrong, a pattern it reaches for that's quietly a mistake, a fresh instance is prone to the same error and won't flag it, because it doesn't see it as an error either. Fresh context catches context-bound mistakes. It does not catch model-level ones.
So correctness in this loop rests on three things doing three different jobs. The fresh reviewer guards against the fixer's tunnel vision and the weaknesses the tests don't reach. The green suite guards against behavioral regressions. And the error neither fully catches, the model being confidently and consistently wrong in a way both instances share, is exactly what my own judgment at the test layer is for: the coverage I demand up front, and the gaps I find by driving the software each cycle. That's the layer I kept for myself. Deciding what the suite has to cover means asking what failure modes aren't represented anywhere, which is a harder discipline than reading an implementation, not an easier one.
The human judgment didn't disappear when I stopped reading code. It concentrated into the one decision the agents can't make for me, because they'd make it with the same blind spots that produced the code. That decision got more important, not less.
One more note, since anyone who's tried it will know: the higher tiers are expensive. End-to-end and acceptance tests burn real time and tokens, far more than unit tests, so a lot of the work was deciding when each tier was worth running and writing those rules into the project config so the system applied them without me.
What I will and won't claim
I won't tell you this is production-ready, because I don't fully believe it is. It's on the edge of what's currently possible. Sometimes the loop converges cleanly, sometimes it needs a human to break a stalemate the agents talk themselves into. The honest claim is narrower than the demo would suggest: this loop reliably produces code that passes a suite I trust, and I trust the software because of that suite and the hours I spend driving it myself, not because I watched the code get written. That trust is exactly as good as the bar I set, and not one bit better.
But it is substantially more capable than the same workflow would have been even a short while ago. The interesting question for anyone building software right now isn't whether to let a model write the code. It's where the last irreplaceable human decision sits, and how much rides on getting it right. For me, on this build, it sat at the test layer and never moved: the coverage I demanded at the start, and every test I added after the software showed me something I'd missed. The agents wrote everything else. What they built was bounded not by the code I declined to read, but by the bar I kept raising.